Steven Miller sjmiller@math.ohio-state.edu
I.
Introduction:
We’ve
seen that not every matrix is diagonalizable. For example, consider
(0 1)
(0 0)
Then
direct calculation shows that it is not diagonalizable. Why do we care about
diagonalizing matrices? The main reason is ease of computation. If we can write
A = S L S-1, then A1000 = S L1000 S-1, and the calculations can be performed very quickly. If we had to
multiply 1,000 powers of A, this would be very time consuming. Theoretically,
we may not need such a time-saving method, but if we’re trying to model any
physical system or economic model, we’re going to want to run calculations on a
computer. And if the matrix is decently sized, very quickly these calculations
will cause noticeable time-lags.
Jordan
Canonical Form is the answer. The Question? What is the ‘nicest’ form we can
get an arbitrary matrix into. We already know that, to every eigenvalue, there
is a corresponding eigenvector. If an nxn matrix has n linearly independent
eigenvectors, then it is diagonalizable. Hence,
Theorem 1: If an nxn matrix A has n distinct
eigenvalues, then A is diagonalizable, and for the diagonalizing matrix S we
can take the columns to be the n eigenvectors (S-1 A S = L).
In
the proof of the above, we see all we needed was n linearly independent
vectors. So we obtain
Theorem 2: If an nxn matrix A has n linearly
independent eigenvectors, then A is diagonalizable, and for the diagonalizing
matrix S we can take the columns to be the n eigenvectors (S-1 A S =
L).
Now
consider the case of an nxn matrix A that does not have n linearly independent
eigenvectors. Then we have
Theorem 3: If an nxn matrix does not have n linearly
independent eigenvectors, then A is not diagonalizable.
Proof:Assume A is diagonalizable by the
matrix S.
Then S-1 A S
= L, or A = S L S-1.
The standard basis vectors e1,
..., en are eigenvectors of
L, and as S is invertible, we get Se1,
..., Sen are
eigenvectors of A, and these
n vectors are linearly
independent. (Why?) But this contradicts the fact that
A does not have n linearly
independent eigenvectors.
Contradiction, hence A is not
diagonalizable.
So,
in studying what can be done to an arbitrary nxn matrix, we need only study
matrices that do not have n linearly independent eigenvectors.
Let A be an
nxn matrix. Then there exists an invertible matrix M such that M-1 A
M = J, where J is a block diagonal matrix, and each block is of the form
(l 1 )
( l 1
)
( l 1 )
( . . . )
( l 1)
( l)
Note
J1000 is much easier to computer than A1000. In fact,
there is an explicit formula for J1000 if you know the eigenvalues
and the sizes of each block.
II. Notation:
Recall
that l is an eigenvalue of A if Det(A - lI) = 0, and v is an eigenvector of A with
eigenvalue l if Av = lv. We say v is a generalized eigenvector of A
with eigenvalue l if there is some number N
such that (A-lI)N v = 0. Note all eigenvectors
are generalized eigenvectors.
For
notational convenience, we write gev
for generalized eigenvector, or l-gev for generalized eigenvector
corresponding to l.
We
say the l-Eigenspace of A is the subspace spanned by the eigenvectors of A that have eigenvalue l. Note
that this is a subspace, for if v and w are eigenvectors with eigenvalue l, then av + bw is an eigenvector with
eigenvalue l.
We
define the l-Generalized
Eigenspace of A to be the subspace of vectors killed by some power of (A-lI). Again, note that this is a subspace.
III. Needed Theorems:
Fundamental Theorem of
Algebra:
Any polynomial with complex coefficients of degree n has n complex roots (not
necessarily distinct).
Cayley-Hamilton Theorem: Let p(l) = Det(A-lI) be the characteristic
polynomial of A. Let l1, ..., lk be the distinct roots of
this polynomial, with multiplicities n1, ...., nk (so n1
+ ... + nk = n). Then we can factor p(l) as
p(l) = (l - l1) n1 (l - l2) n2 * ... * (l - lk) nk,
and the matrix A satisfies
p(A) = (A - l1I) n1 (A - l2I) n2 * ... * (A - lkI) nk = 0,
Schur’s Lemma
(Triangularization Lemma): Let A be an nxn matrix. Then there exists a unitary U such that U-1
A U = T, where T is an upper triangular matrix.
Proof:
construct U by fixing one column at a time.
IV. Reduction to Simpler Cases:
In
the rest of this handout, we will always assume A has eigenvalues l1, ..., lk, with multiplicities n1,
...., nk (so n1 + ... + nk = n). We will show
that we can find n1 l-gev, n2 l-gev, ..., nk l-gev, such that these n vectors are linearly
independent (LI). These will then form our matrix M.
So,
if we can show that the n generalized eigenvectors are linearly independent,
and that each one ‘block diagonalizes’ where it should, it is enough to study
each l separately.
For
example, we’ll show it’s sufficient to consider l = 0. Let l be an eigenvalue of A. Then if vj
is a generalized eigenvector of A with eigenvalue l, then vj is a generalized
eigenvector with eigenvalue 0 of B = A - lI:
A vj = l vj + vj-1 à B vj = 0 vj + vj-1.
So,
if we can find nj LinIndep gev for B corresponding to 0, we’ve found
nj LinIindep gev for A corresponding to l.
The
next simplification is that if we can find nj LinIndep gev for U-1 B U, then
we’ve found nj LinIndep gev for B. The proof is a straightforward
calculation: let v1, ..., vm be the m LinIndp gev for U-1
B U; then U-1 v1,
...., U-1 vm will be m LinIndep gev for B.
Lemma 4: Let p(l) = (l - l1) n1 (l - l2) n2 * ... * (l - lk) nk
be the char poly of A, so p(A) = (A - l1I) n1 (A
- l2I) n2
* ... * (A - lkI) nk. For 1 £ i £ k, consider (A - liI). This
matrix has exactly ni LinIndep generalized eigenvectors with
eigenvalue 0, hence A has ni LinIndep generalized eigenvectors with
eigenvalue li.
Proof:
For notational simplicity, we’ll prove this for l = l1, and let’s write m for the
multiplicity of l (so m = n1).
Further, by the above arguments we see it is sufficient to consider the case l = 0. By the Triangularization Lemma, we can
put B = A - lI (which has first
eigenvalue = 0) into upper triangular form. What we need from the proof is that
if we take the first column of U to be v, where v is an eigenvector of B
corresponding to eigenvalue 0, then the first column of T = U1-1
B U1 would be (0,0, ..., 0)T.
The
lower (n-1)x(n-1) block of Tn, call it Cn-1, is upper
triangular, hence the eigenvalues of B appear as the entries on the main
diagonal. Hence we can again apply the triangularization argument to Cn-1,
and get an (n-1)x(n-1) unitary matrix U2b, such that U2b-1
Cn-1 U2b = Tn-1 has first column (0,0,....0),
and the rest is upper triangular. Hence we can form an nxn unitary matrix U2
(1 0 0 ... 0)
(0
)
(0 U2b )
(...
)
(0
)
Then
U2-1 U1-1 B U1 U2
=
(0 * * ... *)
(0 0 * ... *)
(0 0 * ... *)
(... ... ...
... )
(0 0 0 ... *)
The
net result is that we’ve now rearranged our matrix so that the first two
entries on the main diagonal are zero. By ‘triangularizing’ like this m times,
we can continue so that the upper mxm block is upper triangular, with zeros
along the main diagonal, and the remaining entries on the main diagonal are
non-zero (as we are assuming the multiplicity was m). Call this matrix Tm.
Note there is a unitary U such that Tm = U-1BU. Remember, Tm and B are nxn matrices, not mxm matrices.
Sublemma 1: At most m
vectors can be killed by powers of Tm.
Proof:
direct calculation: When we multiply powers of Tm, we still have an
upper triangular matrix. The entries on the main diagonal are zero for the
first m terms, and then non-zero for the remaining terms (because the
multiplicity of the eigenvalue l = 0 is exactly m). Hence
the vectors em+1, em+2, ..., en are not killed
by powers of Tm, and so powers of Tm can have a nullspace
of dimension at most m.
We
now show that exactly m vectors are killed by Tm. This follows
immediately from
Sublemma 2: Let C be an mxm
upper triangular matrix with zeros along the main diagonal. Then Cm
is the zero matrix.
Proof:
straightforward calculation, left to the reader.
Hence
the nullspace of (Tm)m (and all higher powers) is exactly m, which
proves there are m generalized eigenvectors of B with eigenvalue l = 0. These vectors are LinIndep: As Tm
is upper triagonal with zeros on the main diagonal for the first m entries, Tm
has m LinIndep gev e1, …, em with eigenvalue 0. As B = UTmU-1,
B has m LinIndep gev Ue1, …, Uem with eigenvalue 0 (show
that B cannot have any more LinIndep gev with l = 0).
Returning
to the proof of Lemma 4, we see that there are exactly n1 vectors
killed by (A-l1I)n1, ...., nk
vectors killed by (A-lkI)nk.
The
only reason we go thru this triagonalizing is to conclude that there are
exactly ni vectors killed by (A-liI)ni. Try to prove this fact directly!
IV. Appendix: Representation
of l-Generalized Eigenvectors.
We
know that if l is an eigenvalue with
multiplicity m, there are m generalized eigenvectors, satisfying (A - lI)m v = 0. We describe a very
useful way to write these eigenvectors. Let us assume there are t eigenvectors,
say v1, …., vt. We know there are m l-gev. Note if v is a l-gev, so is (A-lI)v, (A-lI)2 v, …., (A-lI)m v. Of course, some of these
may be the zero vector.
We
claim that each eigenvector is the termination of some chain of l-gev. In particular, we have
(A-lI) v1,a = v1,a-1
(A-lI) v1,a-1 = v1,a-2
...
(A-lI) v1 = 0 where v1 = v1,1.
and
(A-lI) v2,b = v2,b-1
(A-lI) v2,b-1 = v2,b-2
...
(A-lI) v2 = 0 where v2 = v2,1.
all
the way down to
(A-lI) vt,r = vt,r-1
(A-lI) vt,r-1 = vt,r-2
...
(A-lI) vt = 0 where vt = vt,1,
and
a + b + …+ r = m.
We emphasize that we have
not shown that such a sequence of l-gev exists. Later we shall show how to construct these vectors, and
then in Lemma 8 we will prove they are Linearly Independent. For now, we assume
their existence (and linear independence), and complete the proof of Jordan
Canonical Form.
Let
us say a l-gev is a pure-gev if it is not an eigenvector. Thus, in
the above we have t eigenvectors, and m-t pure-generalized eigenvectors. For
notational convenience, we often label the l-generalized eigenvectors by
v1,
…, vm. Thus, for a given j, we have (A-lI)vj = 0 if vj is an
eigenvector, and (A-lI)vj = vj-1 if
vj is a pure-gev.
V. Linear Independence of
the l-Generalized Eigenspaces.
Assume the n1 gev
corresponding to l1 are linearly independent
amongst themselves, and the same for the n2 gev corresponding to l2, .... We now show that the
n gev are linearly independent. This fact complete the proof of Jordan
Canonical Form (of course, we still must prove the ni li-gev are linearly
independent).
Assume
we have some linear combination of the n gev equaling zero. By
LC li-gev we mean a linear
combination of the ni li-gev. (This is just to
simplify notation).
Then
(LC l1-gev) + (LC l2-gev) + ... + (LC lk-gev) = 0.
We’ll
show first that the coefficients in the first linear combination are all zero.
Recall the characteristic polynomial is
p(A) = (A - l1I) n1 (A - l2I) n2 * ... * (A - lkI) nk.
Define
g1(A) = (A - l2I) n2 (A - l3I) n3 * ... * (A - lkI) nk,
g1(A)
kills (LC l2-gev), g1(A)
kills (LC l3-gev),...., g1(A)
kills (LC lk-gev).
Why?
For example, for the l2-gev, they are all killed by
(A-l2I)n2, and hence
as g1(A) contains this factor, they are all killed.
What
does g1(A) do to (LC l1-gev)? Again, for notational
simplicity we’ll write m for n1, and v1, ..., vm
for the corresponding m l1-gev.
We
can look at it factor by factor, as all the different terms (A - liI) commute.
Lemma 5: For i > 1, let the vj’s be the gev corresponding to l1.
If vj is a
pure-gev, then (A - liI) vj = (l1 - li) vj + vj-1
If vj is an
eigenvector, then (A - liI) vj = (l1 - li) vj .
Again,
the proof is a calculation: if vj is a pure-gev,
(A - liI) vj = (A - l1I + l1I - liI) vj
= (A - l1I) vj + (l1I - liI) vj
= vj-1 + (l1 - li) vj
The
proof when vj is an eigenvector is similar.
Now
we examine g1(A) ((LC l1-gev) + (LC l2-gev) + ... + (LC lk-gev)) = 0.
Clearly
g1(A) kills the last k-1 linear combinations, and we are left with
g1(A) (LC l1-gev) = 0
Let’s
say the LC l1-gev = a1 v1
+ ... + am vm. We
need to show that all the aj’s are zero. (Remember we are assuming the vj’s are linear independent –
we will prove this fact when we construct the vj’s). Assume am
¹ 0. From our labeling, vm is
either an eigenvector, or a pure-gev that starts a chain leading to an
eigenvector: vm, (A - liI) vm, (A - liI)2 vm, …. Note
no other chain will contain vm.
We
claim that g1(A) (LC l1-gev) will contain a
non-zero multiple of vm. Why? When each factor (A - liI) hits a vj, one
gets back (l1 - li) vj + vj-1
if vj is not an eigenvector, and (l1 - li) vj if vj
is an eigenvector. Regardless, we always get back a non-zero multiple of vj,
as l1 ≠ li.
Hence
direct calculation shows the coefficient of vm in g1(A)
(LC l1-gev) is
am (l1 - l2)n2 (l1 - l3)n3 * ... * (l1 - lk)nk
As
we are assuming the different l’s are distinct (remember we
grouped the eigenvalues together to have multiplicity), this coefficient is
non-zero. As we are assuming v1 thru vm are linearly
independent, the only way the coefficient of vm can be zero is if am
= 0. Similar reasoning implies am-1 = 0, and so on. Hence we have
proved:
Theorem 5: Assuming that the
ni generalized eigenvectors associated to the eigenvalue li are linearly
independent (for 1 £ i £ n), then the n generalized
eigenvectors are linearly independent. Furthermore, there is an invertible M
such that M-1 A M = J.
The
only item not immediately clear is what M is. As an exercise, show that one may
take M to be the generalized eigenvectors of A. They must be put in a special
order. For example, one may group all the l1-gev together, the l2-gev together, and so on.
For each i, order the li-gev as follows: say there
are t eigenvectors which give sequences v1, …, v1,a, v2,
…, v2,b,…, vt,…,vt,r. Then this ordering works
(exercise).
VI. Finding the l-gev:
The
above arguments show we need only find the ni generalized
eigenvectors corresponding to the eigenvalue li; these will be of the form
(A-liI) vj = 0 or (A-liI) vj = vj-1.
Moreover, we’ve also seen we may take li = 0 without loss of
generality. For notational convenience, we write l for li and m for ni.
So
we assume
the multiplicity of l = 0 to be m. Hence in the sequel we show
how to find m generalized eigenvectors of an mxm matrix whose mth
power vanishes. (By the triangularizing we’re done, finding m such generalized
eigenvectors for this is equivalent to finding m generalized eigenvectors for
the original nxn matrix A).
We
define the following spaces, where A is our mxm matrix:
1. N(A) = Nullspace(A). The dimension of this is the number of
eigenvectors, as we are assuming l = 0.
2. V1 = W1 =
N(A)
3. Vi = N(Ai),
all vectors killed by Ai. Note that Vm is the entire
space.
4. Wi = {w Î N(Ai) such that w ^ N(Ai-1)}, for 2 £ i £ m.
For
example, assume we are in R3,
and A2 is the zero matrix. Let’s consider V2. For
definiteness, assume V1 is 1-dimensional, and V2 is
3-dimensional. W1 is just V1. The problem is, if y1
and y2 are two vectors killed by A2 and not by A, then it
is possible that y1 - y2 (or some linear combination) is
killed by A.
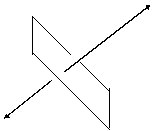
In
the picture above, the line represents W1 and the plane represents W2.
Anything in the 3-space above is killed by A2, and only those vectors along the line are
killed by just A.. It is possible to take two vectors in R3 that are
linearly independent, neither of which lie on the line, but their difference does lie on the line.
Why
are we constructing such spaces as W2? Why isn’t V2 good
enough? The reason is we want a very nice basis. The first basis vector will
just be a vector in V1 = W1. For the other two
directions, we can take two vectors perpendicular to W1. (How? This
is a 3-dimensional space – simply apply Gram-Schmidt).
The
advantage of such a basis is that if z1 and z2 are
linearly independent vectors in W2, then the only way a z1
+ b z2 can be in W1 is for a = b = 0. Why? W2
is a subspace, and as z1 and z2 are perpendicular to W1,
so is their linear combination. So their linear combination is still in the
plane perpendicular to W1, and as long as a and b are not both zero,
it will not be the zero vector in the plane, hence it will be killed by A2
and not A.
What
we are really doing is Partial Orthogonal
Complementation. Instead of finding the orthogonal complement of V1
in Rm, we are finding the orthogonal complement in V2.
Let L be the smallest
integer such that AL is the
zero matrix.
Then we only need to look up to WL and VL. VL will be an m-dimensional space
(as every vector is killed by AL). We’ll have a nice basis for VL,
consisting of the bases of W1, ..., WL. The advantage of
this decomposition is that the spaces are mutually perpendicular, and if you
have a linear combination of vectors in Wj, then the only way it can
be in a Wb with b < j is if the combination is the zero vector.
Lemma 6: dim(Wi-1)
³ dim(Wi), for i = 2, 3, ..., L.
Proof:
Assume not: let N = dim(Wi). So consider a basis of Wi: z1,
z2, ..., zN, and the vectors Az1, ..., AzN.
Clearly each Azj is in Vi-1. We claim each Azj
must have some component in Wi-1. Why? The smallest power that kills
each zj is Ai. If there was no component in Wi-1,
then Ai-2 would kill zj, contradiction.
Let
P = Pi-1 be the projection operator from Vi-1 to Wi-1.
Note P2 = P, and by the above arguments each vector Az1,
..., AzN has a non-zero component in Wi-1. Therefore the
N vectors PAz1, ..., PAzN are N non-zero vectors in Wi-1.
As
we are assuming that dim(Wi-1) < dim(Wi), the N
vectors PAz1 thru PAzN cannot be linearly independent,
for the dimension of a subspace is the maximal number of linear independent
vectors you can have in that space. Hence there exist constants, not all zero,
such that
a1 PAz1
+ ... + aN PAzN = 0
Hence
PA (a1z1 + ... + aNzN) = 0. By the
definition of Wi, the linear combination a1z1 +
... + aNzN is in Wi. Therefore, the smallest
power of A that kills it is I unless
it is the zero vector. As we are assuming the vectors z1
through
zN are linearly independent, it is only the zero vector if a1
= ... = aN = 0.
As i
> 1, A cannot kill a1z1
+ ... + aNzN unless this is the zero vector. Could
PA kill a non-zero vector? No: by definition, if a1z1 +
... + aNzN is not the zero vector, then it is in Wi.
Therefore A(a1z1 + ... + aNzN) has
a non-zero component in Wi-1 (if not, that contradicts a1z1
+ ... + aNzN is in Wi). Therefore, PA(a1z1
+ ... + aNzN) cannot be zero, as A(a1z1
+ ... + aNzN) has a component in Wi-1. Therefore,
the only way PA(a1z1 + ... + aNzN) can
be the zero vector is if a1z1 + ... + aNzN
is the zero vector, which forces a1 = ... = aN = 0. Contradiction.
QED.
REMARK: by Lemma 6, we see our
previous example is impossible. An example that is consistent with Lemma 6 is
to consider R5, let V1 = W1 be
three-dimensional, and W1 a plane perpendicular to W1.
Lemma 7: dim(Wi) ³ 1 for i = 1, 2, ..., L.
Proof:
As L is the smallest integer such that AL is the zero matrix, then
there must be a vector killed by AL but not by AL-1.
Whence dim(WL) is at least 1, so by Lemma 6 we obtain dim(Wi)
is at least 1 for i = 1, 2, ..., L.
We
now show how to construct the m generalized eigenvectors. We find bases for the
spaces W1, W2, ..., Wm. We then use A to
‘pullback’.
It’s
easier to explain by an example: assume the dimensions are as follows. Let’s
take m = 12, and L = 5. For definiteness sake, consider the following:
V1 V2 V3 V4 V5 V6
W1 W2 W3 W4 W5 W6
dimW: 4 3 2 2 1 0
basis: u1,...,u4 v1,...,v3 w1,w2 x1,x2 y
pullback:A4 y ß A3 y ß A2 y ß A y ß y
Now,
W4 is 2-dimensional.
WE DO NOT KNOW THAT Ay IS IN
W4 !!! IT IS QUITE POSSIBLE THAT Ay IS KILLED BY A4 AND
NO SMALLER POWER OF A WITHOUT BEING IN W4 !!!
We
know y is killed by A5 and no smaller power of A; hence Ay is killed
by A4 and no smaller power of A. But this does not mean that Ay is
in W4.
Fortunately,
there is a huge degree of non-uniqueness in the Jordan Canonical Form. We did
not need Ay to be in W4 – all we needed was Ay (and A2y,
A3y, ...) to be killed by A4 and nothing lower (A3
and nothing lower, ....). We’ll see below how to handle this.
So
for now, all we know is that Ay is in V4, with a non-zero projection
in W4; that A2 y is in V3 with a non-zero
projection in W3, and so on.
W4
is 2-dimensional. Choose a vector x in W4 such that x is linearly
independent with the projection of Ay onto W4. Then this x gives us
another Jordan Block:
V1 V2 V3 V4 V5 V6
W1 W2 W3 W4 W5 W6
dimW: 4 3 2 2 1 0
basis: u1,...,u4 v1,...,v3 w1,w2 x1,x2 y
pullback A4 y ß A3 y ß A2 y ß A y ß y
pullback A3 x ß A2 x ß A x ß x
We
continue the game (noting that Ax is in V3, but not necessarily in W3).
We already have two candidates for directions in V3, namely A2y
and Ax. We’ll show later that though they are not necessarily in W3,
they are killed by A3 and not A2, and that their
projections onto W3 are linearly independent.
We
need to find 3 directions in W2. The projections of A3y
and A2x give us at most two (these two directions could be the same
– again, we will show later that this cannot happen). As W2 is a 3
dimensional space, we can find a vector v in W3 that is linearly
independent with the projections of A3y and A2x:
V1 V2 V3 V4 V5 V6
A4 y ß A3 y ß A2 y ß A y ß y
A3 x ß A2 x ß A x ß x
A v
ß v
We
then have to find four directions in W1, and have three candidates.
We’ll see later these three candidates are linearly independent, hence we can
find a fourth vector u linearly independent with the rest:
V1 V2 V3 V4 V5 V6
A4 y ß A3 y ß A2 y ß A y ß y
A3 x ß A2 x ß A x ß x
A v
ß v
u
We
now have enough (m) candidates. We will show that they are linearly
independent.
First
we prove that A2 y and Ax are linearly independent; then we will
prove A3 y, A2 x are linearly independent, and so on.
(Proof suggested by L. Fefferman and O. Pascu). Assume a A2 y + b Ax
= 0. Then A(a Ay + b x) = 0. But Ay has a non-zero projection in W4,
and we’ve chosen x to be linearly independent in W4 with the
projection of Ay. Therefore the smallest power that can kill this combination
is A4, unless it is the
zero combination. Hence the only way this can be killed by A is if a = b = 0.
Similarly,
assume a A3 y + b A2 x = 0. Then A2(a Ay + b
x) = 0, and by the same argument as above, a = b = 0. Note that we did not need
Ay to be in W4, only that it had a non-zero projection there.
By
construction, v is linearly independent with A3 y and A2
x. What about A4y, A3x, and Av? Assume a A4y +
b A3x + cAv = 0. Then again we obtain A(aA3y + bA2x
+ cv) = 0, and the construction of v forces a = b = c = 0.
Lemma 8: Assume now some
linear combination of the m generalized eigenvectors constructed above is zero.
Then all the coefficients are zero.
Proof:
V1 V2 V3 V4 V5 V6
A4 y ß A3 y ß A2 y ß A y ß y
A3 x ß A2 x ß A x ß x
A v
ß v
u
Assume
the coefficient of y, a, is non-zero. Then we have
a y = - (rest of terms), where the
rest is killed by A4, but y isn’t.
Hence
a must be zero.
Now
assume the coefficients of Ay and x are a and b, respectively. Then
a Ay + b x = - (rest of terms), rest
killed by A3.
As
x is linearly independent with the projection of Ay onto W4, a Ay +
bx is killed by A4 and not A3
unless this combination is the zero
vectory. As the rest of the terms are
killed by A3 , this implies a = b = 0.
Continuing
to argue in this way, we obtain all the coefficients are zero, and hence the
generalized eigenvectors are linearly independent.
We
can now build up our matrix M and J! At last!
For
each l, we have associated generalized
eigenvectors. For definiteness sake, let’s consider the above case, and I’ll
leave to you the generalization. We have 4 blocks corresponding to l = 0: one block with 5 generalized
eigenvectors (starting with the eigenvector A4y, and ending with y),
another block with 4 gev (starting with the eigenvector A3x, and
ending with x), another block of length 2, and one of length 1.
We
can order the blocks anyway we want – that will just change the order of the
block in J; however, in each block we must write the vectors starting with the
eigenvector on the far left, and going to the highest generalized eigenvector
on the far right:
( A4y A3y A2y Ay
y A3x A2 x Ax
x Av v
u )
Another
possible arrangements would be
( A3x A2 x Ax x A4y A3y A2y Ay y
Av v
u )
and
so on. I’ll leave it to you to verify that M-1 A M = J.
VII. Calculation Shortcut:
When
trying to find bases for the spaces Wi, there is a nice shortcut.
First, we find a basis for Vi, or start to. How do we find vectors
killed by Ai? We just have to find the nullspace of Ai.
We do this by Gaussian Elimination, reducing Ai to an upper
triangular matrix U. We can assume we’ve already found bases for W1
thru Wi-1, or equivalently, a basis for Vi-1. Let’s say
the basis for Vi-1 is b1, b2, ..., bq.
Then if we add these q rows to U, forming a new matrix U’, we observe the
following:
(1)
If U’ v = 0, then v is
killed by Ai (from the first m rows of U’ are the same as those of U).
(2)
If U’ v = 0, then v is
perpendicular to W1 thru Wi-1: this follows immediately
from the fact that we put the basis for W1 thru Wi-1 as
the last q rows of U’, and so this forces v to be perpendicular to these
spaces.
Also,
if an eigenvalue has multiplicity 3 or less, counting the number of linearly
independent eigenvectors gives us the Jordan Form. Why? If there are 3 LI
eigenvectors, it’s diagonalizable. If there is only 1, it must be a 3x3 block.
If there are 2, we must have a 2x2 and a 1x1 block. Note we have no idea what M
looks like.
Also
note that this argument fails for multiplicity 4 and greater. If we have
multiplicity 4 and 2 eigenvectors, it could be 2x2, 2x2, or it could be 3x3,
1x1.
Note
the difference between theory and practice: theoretically, we know that bases
for the different Wi exist, so with a wave of the hand we have them
to work with. But if we were actually going to Jordanize large matrices,
finding bases for all these spaces takes time, and we don’t always need all
those basis elements. Often it’s enough to just find vectors in Vi;
for example, show that if instead of taking y in WL we took y in VL
the pullback process would work. Then there could be many i where we’ve
pulled-back all the vectors we need, and hence there would be no need there to
find a basis. If this doesn’t make too much sense, don’t worry: it’s late at
night here for me, and at this stage in your life, you won’t be dealing with
terrible Jordanizations where this would really make a difference. I just want
to emphasize that often you can come up with a theoretical line of argument
that, in practice, will yield the correct answer, but be so computationally
inefficient that a better way is greatly desired.
SUMMARY: HOW TO JORDANIZE:
STEP 1: Find the eigenvalues, their
multiplicities, and all the eigenvectors.
STEP 2: For each eigenvalue l and it’s multiplicity m, calculate (A-lI),
(A-lI)2, ..., (A-lI)m.
STEP 3: Find bases for the spaces Wi
described above. This will yield bases
for Vi. Use the
calculation shortcut to find the bases.
STEP 4: ‘Pullback’ vectors as
described, add in vectors linearly
independent with projections as needed.